타이타닉 침몰
1912년 4월, 정확히는 4월 10일은 타이타닉호의 첫 항해이자 마지막 항해이었다. 모든 이들이 아는 타이타닉 침몰 사건이 그 날 일어났다. 아직까지도 많은 사람들에게 회자되며, 영화로까지 만들어져서 대다수가 알고 있다. 타이타닉호가 침몰하게 됐을 때, 과연 어떤 사람들이 살아남고, 몇명의 사람들이 살아남았는지 궁금해졌다. 그리고 머신러닝 예제에서 가장 흔하게 볼 수 있는 "타이타닉 생존자 예측"을 Python을 통해 알아 볼 것이다. 아래 영상을 본다면 도메인 지식을 높이는데 조금이라도 도움이 될 것 이다.
머신러닝(Machine Learning) 그리고 타이타닉(Titanic)
파이썬(Python) 모듈 세팅
# 모듈세팅 import numpy as np import pandas as pd # 모듈세팅 import numpy as np import pandas as pd # 전처리 import missingno as msno from collections import OrderedDict from sklearn.preprocessing import StandardScaler # 샘플링 from sklearn.model_selection import train_test_split # 분류기 from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC # 측정 from sklearn.metrics import accuracy_score |
분석을 위한 Numpy, Pandas, Sklearn 그리고 Missing Value(결측치)를 다루기 위한 missingno 모듈등을 준비해둔다.
%matplotlib inline sns.set(color_codes=True) pal = sns.color_palette("Set2", 10) sns.set_palette(pal)
TitanicTrain = pd.read_csv("train.csv") TitanicTrain.columns, TitanicTrain.shape |
그리고 위를 통해 데이터셋의 변수들과 데이터의 총 개수를 도출해 낼 수 있다. 총 891개의 행(row)과 13개의 열(col)로 이루어져 있다는 것을 알 수 있다.
# 타이타닉 학습데이터 개요 TitanicTrain.info() |

간단하게 변수들에 대해서 알아보자.
– Survival: Survival 0 = No, 1 = Yes ( 예측하고자 하는 변수, 종속변수임 )
– Pclass: 사회적 지위를 나타냄(1st = Upper, 2nd = Middle, 3rd = Lower)
– Ticket class: 몇등석인지를 나타냄 (1 = 1st, 2 = 2nd, 3 = 3rd)
– Sibsp: 자매, 배우자와 같이 승선해있는 사람의 수를 말한다
– Parch: 타이타닉에 탑승 한 부모 / 아이들의 수 (일부 어린이는 유모와 동행했기 때문에 그들은 parch = 0)
– Ticket: 티켓번호
– Fare: 여객운임
– Cabin: 선실 번호
– Embarked: 승선한 장소를 말한다. C = Cherbourg, Q = Queenstown, S = Southampton
결측치 찾기
# 미싱데이터 찾기 msno.matrix(TitanicTrain) |
총 891개의 데이터인데 변수별로 Missing Value(결측치)가 존재한다. 이를 missingno를 통해 시각화하여 확인할 수 있다.
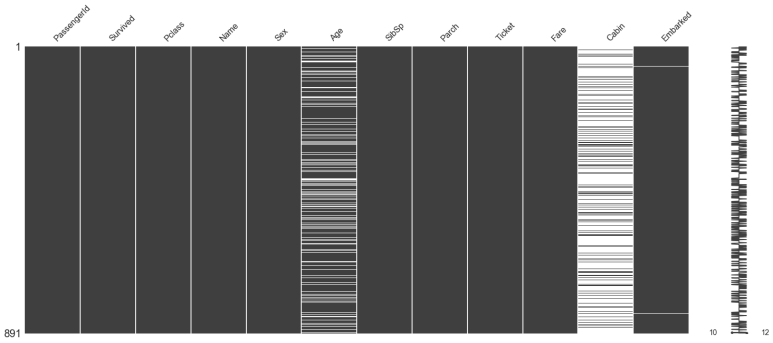
Missing Value 확인
흰색의 줄이 결측치를 의미한다. Age, Cabin, Embarked에서 결측치를 확인할 수 있다. 그렇다면 이러한 결측치들을 어떻게 처리해야할까? 결측치를 제외하고 분석하거나, 평균값, 중앙값으로 대체를 하는 등 여러가지 방법이 있지만 여기서는 중앙값을 이용하여 분석할 것이다. 다음 순서로 넘어가기전에 이후에 할 분석에 대해 알아보자.
1. Univariate 는 변수가 여러개라는 뜻이다. 그 중에서도 독립변수를 말한다. 즉, 독립변수가 여러 개인 경우의 분석 기법일 때에 univaite 라는 말을 사용하게 된다.
2. Bivariate 는 변수가 2개라는 뜻이다. 그중에서도 주로 대등한 변수가 2개 있을 때 사용하는 용어이다. 대표적인 예가 상관분석이다. 상관분석은 두 변수 사이의 관계를 규명하는 분석이다.
Univariate 분석
# 범주형 / 연속형 데이터 분류 categ = ['Pclass','Sex','SibSp','Parch','Embarked'] conti = ['Fare','Age']
# 분포 fig = plt.figure(figsize=(15,15)) for i in range(0,len(categ)): fig.add_subplot(3,3,i+1) sns.countplot(x=categ[i], data=TitanicTrain)
for col in conti: fig.add_subplot(3,3,i+2) sns.distplot(TitanicTrain[col].dropna()); i += 1
plt.show() fig.clear() |
먼저 분석에 사용할 변수들을 범주형 / 연속형 데이터로 구분한다. 그리고 나눈 변수들에 대한 데이터를 시각화하여 데이터를 훑어보자.
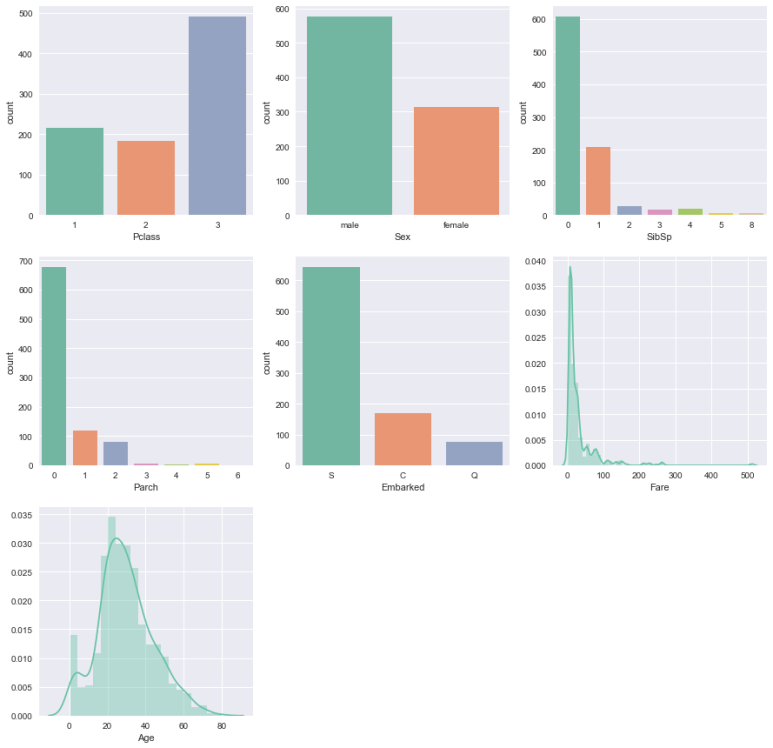
시각화
직관적으로 3등석이 더 많고, 남성이 더 많다는 등 다양한 정보를 도출해 낼 수 있다. 이러한 인사이트를 알고 있다면 추후 이루어질 분석에 큰 도움이 될 것이다.
Bivariate 분석
fig = plt.figure(figsize=(15,15)) i = 1 for col in categ: if col != 'Survived': fig.add_subplot(3,3,i) sns.countplot(x=col, data=TitanicTrain, hue='Survived'); i += 1
# 박스플롯 x= Age 일 때 Survived fig.add_subplot(3,3,6) sns.swarmplot(x='Survived',y="Age",hue='Sex',data=TitanicTrain) fig.add_subplot(3,3,7) sns.boxplot(x='Survived', y='Age', data=TitanicTrain)
# Fare ~ Survived fig.add_subplot(3,3,8) sns.violinplot(x='Survived', y='Fare', data=TitanicTrain)
# 변수간의 상관관계 corr = TitanicTrain.drop(['PassengerId'], axis=1).corr() mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True cmap = sns.diverging_palette(220, 10, as_cmap = True) fig.add_subplot(3,3,9) sns.heatmap(corr,mask=mask,cmap=cmap,cbar_kws={"shrink": .5}) |
추가적으로 다양한 plot들을 이용하여 Survived 와 범주형 변수 / 연속형 변수들간의 관계를 나타낼 것이다. 그리고 변수들간의 서로가 가지는 상관관계의 정도를 Heatmap을 통해 볼 수 있다. ( 기존 그래프
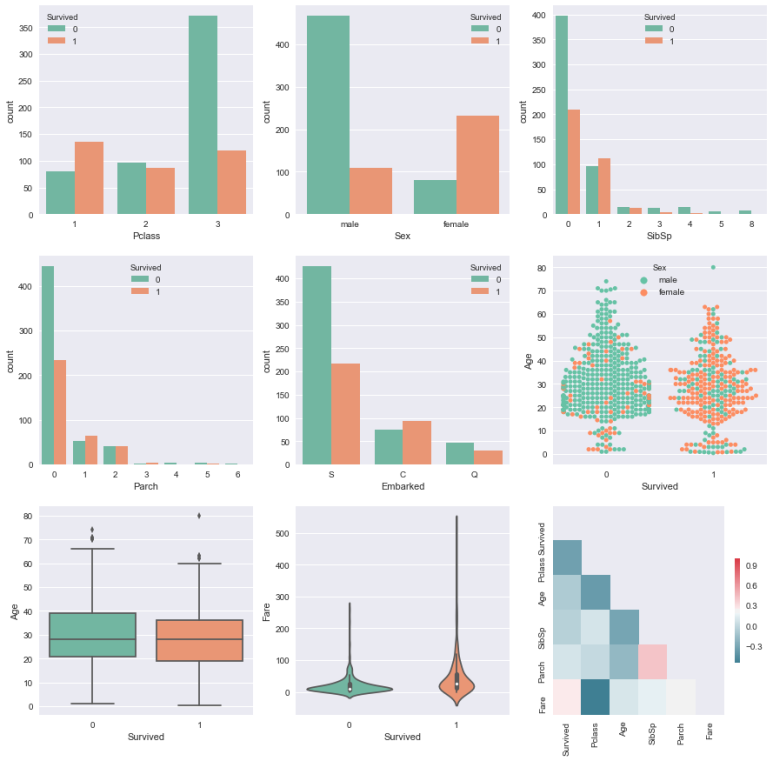
이전의 그래프도 유용했지만 Survived를 기준으로 표시하니 더 유용한 인사이트를 도출해 낼 수 있게 됐다. 먼저 한 눈에 보이는 것은 3등석의 사람들이 많이 살아남지 못했다는 것, 여성보다 굉장히 많은 남성들이 살아남지 못했다는 것등 그래프를 통해 알 수 있다. 그리고 변수들간의 상관관계에 관해서, "Survived"와 "Fare"과 "Pclass"가 강한 상관관계를 가진다는 것을 알 수 있습니다. "Fare"과 "Pclass"는 강한 상관관계를 가지고 있으며, 상류층 사람들이 선형적으로 돈을 더 많이 쓰고 있음을 보여준다.
Feature Engineering
우리는 데이터셋에서 알아 낼 수 있는 새로운 변수를 만들 것 이다. 굉장히 많은 변수들을 만들 수 있지만 여기서는 Title을 통해서 얻을 수 있는 데이터를 사용할 것 이다.
# 새로운 변수 추가하여 효과보기 title = ['Mlle','Mrs', 'Mr', 'Miss','Master','Don','Rev','Dr','Mme','Ms','Major','Col','Capt','Countess']
def ExtractTitle(name): tit = 'missing' for item in title: if item in name: tit = item if tit == 'missing': tit = 'Mr' return tit
TitanicTrain['Title'] = TitanicTrain.apply(lambda row: ExtractTitle(row["Name"]),axis=1) plt.figure(figsize=(13,5)) fig.add_subplot(2,1,1) sns.countplot(x='Title',data= TitanicTrain,hue='Survived'); |
과연 타이타닉호에 탔던 그 사람들의 Title(직위)에 따라 생존이 달라질 것인가?이를 알아보기 위해 Title을 이용하여 Survived와의 관계를 알아보았다. Title이 없을 경우 Mr로 처리하여 진행할 것이다.

직관적으로 보면 알겠지만 Mr의 생존률이 가장 낮다. 하지만 성별을 제외한 다른 직위들에서는 생존확률의 차이를 보이지 않아서 Title을 이용할 필요가 없어보인다. 성별과 다를바 없기에 그대로 Sex 변수를 이용할 것이다.
전처리 마무리하기
앞서 봤던 결측치를 처리하고, 범주형 변수인 Cabin을 Dummy화 하여 분석에 이용할 것이고, 수치형 변수들을 Standadization해주어 분석에 용이하게 할 것 이다.
## 미싱벨류 처리하기 - 중앙값으로 대치 # Age MedianAge = TitanicTrain.Age.median() TitanicTrain.Age = TitanicTrain.Age.fillna(value=MedianAge)
# Embarked ModeEmbarked = TitanicTrain.Embarked.mode()[0] TitanicTrain.Embarked = TitanicTrain.Embarked.fillna(value=ModeEmbarked)
# Fare MedianFare = TitanicTrain.Fare.median() TitanicTrain.Fare = TitanicTrain.Fare.fillna(value=MedianFare)
## 더미변수화 하기 TitanicTrain['Cabin'] = TitanicTrain.apply(lambda x :"No" if pd.isnull(x['Cabin'])) else "Yes" , axis= 1) TitanicTrain = pd.get_dummies(TitanicTrain, drop_first=True, columns=['Sex','Title','Cabin','Embarked'])
## 수치형 변수들 스케일링 해주기 - Standardization 표준화 scale = StandardScaler().fit(TitanicTrain[['Age','Fare']]) TitanicTrain[['Age','Fare']] = scale.transform(TitanicTrain[['Age','Fare']]) ### 전처리 끝 ### |
이로서 전처리는 해결되었고, 본격적인 분석을 위해 데이터를 학습데이터(Training Set), 예측데이터(Test Set)으로 나누는 샘플링(Sampling)을 진행할 것 이다. 그리고 Logistic Regression, Random Forest Classifier, Support Vector Classifier을 이용하여 생존자 예측을 할 것 이다.
샘플링(Sampling)
# 샘플링 (train.set / test.set) Target = TitanicTrain.Survived features = TitanicTrain.drop(['Survived','Name','Ticket','PassengerId'],axis=1)
# training / test set 나누기 X_train, X_test, y_train, y_test = train_test_split(features,Target,test_size = 0.3, random_state=42) Target = TitanicTrain.Survived
MLres = {} def Mlresult(model, score): MLres[model] = score print(MLres)
roc_curve_data = {} def Rocdata(algoname, fpr, tpr, auc): data = [fpr,tpr,auc] roc_curve_data[algoname] = data |
분석에 이용하지 않을 변수들을 다 제거하고 보편적인 방식으로 학습데이터:예측데이터=7:3으로 샘플링 하였다. 그리고 각 모델들의 성능을 확인하기 위해 MLres라는 딕셔너리를 만들었다.
Logistic Regression ( 로지스틱 회귀 )
# Logistic Regression (로지스틱 회귀) logi_reg = LogisticRegression()
logi_reg.fit(X_train, y_train)
y_pred = logi_reg.predict(X_test)
# score accuracy = logi_reg.score(X_test,y_test) Mlresult('Logistic Regression', accuracy) |

Logistic Regression은 0.82 즉 82%의 정확도를 보였다.
Random Forest Classifier ( 랜덤 포레스트 )
# Random Forest Classifier rfc = RandomForestClassifier(n_estimators=100)
rfc.fit(X_train,y_train) y_pred = rfc.predict(X_test)
accuracy = rfc.score(X_test,y_test) Mlresult("RandomForestClassifier",accuracy) |
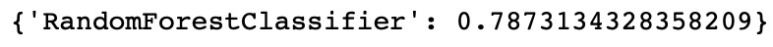
Random Forest Classifier은 앞선 Logistic Regression에 비해 낮은 정확도를 보였다. 0.79로 79%의 정확도를 보였다. ( 실행 할 때마다 정확도는 +-2%정도 변한다 )
Random Forest의 경우 데이터내의 중요변수를 파악할 수 있다.
# 중요변수 파악하기 def FeaturesImportance(data,model): features = data.columns.tolist() fi = model.feature_importances_ sorted_features = {} for feature, imp in zip(features,fi): sorted_features[feature] = round(imp,3) sorted_features = OrderedDict(sorted(sorted_features.items(),reverse=True, key =lambda t: t[1])) dfvi = pd.DataFrame(list(sorted_features.items()), columns=['Features','Importance']) plt.figure(figsize=(15,5)) sns.barplot(x="Features", y='Importance', data=dfvi); plt.xticks(rotation=90) plt.show()
FeaturesImportance(TitanicTrain,rfc) |
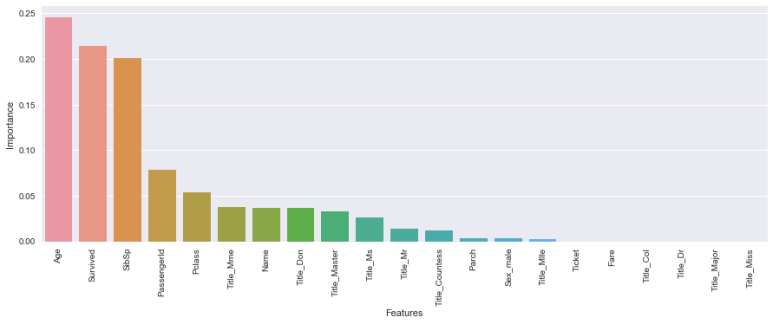
Age가 가장 중요한 변수라는 것을 알 수 있다.
Support Vector Classifier ( Support Vector Machine, 서포트 벡터 머신 )
# Support Vector Machine (SVM) svm = SVC(probability = True) svm.fit(X_train,y_train) y_pred = svm.predict(X_test)
accuracy = svm.score(X_test,y_test) Mlresult("SVC",accuracy) |
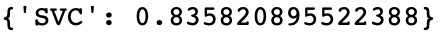
Support Vector Classifier가 가장 높은 정확도인 0.83 즉 83%의 정확도를 보였다.
분석 결론
res = pd.DataFrame({'Model': ['Logistic Regression','RandomForestClassifier','SVC'], 'Score': [0.8283582089552238,0.7873134328358209,0.835820895522388]}) res |

이를 보기 편하게 시각화 해보면
# 결과치 비교 그래프 plt.figure(figsize=(8,5)) sns.barplot(x='Score',y='Model', data = res); plt.xticks(rotation=90) plt.xlim([0.6,0.9]) plt.show() |
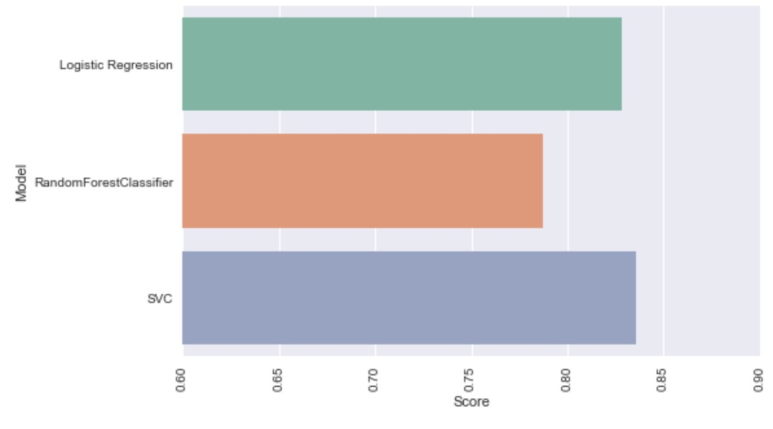
SVC(SVM)이 가장 높은 정확도를 보였고, 그 뒤로 Logistic Regression, Random Forest Classifier 순서로 높은 정확도를 보였다.
결론
머신러닝의 여러가지 알고리즘 중 3가지만을 이용하여 타이타닉 생존자 예측을 해보았다. 다른 알고리즘을 쓴다면 당연히 더 좋은 모델을 만들어 더 좋은 성능을 이끌어 낼 수 있다.


문과생을 위한 머신러닝 : https://academy.elice.io/courses/536/info
엘리스 홈페이지 : https://academy.elice.io/explore

엘리스에서 진행하는 " 문과생을 위한 머신러닝 " 강의에서는 타이타닉 예제와 간단한 예제를 통해 머릿속에 머신러닝에 대한 큰 틀을 구성하는데 도움이 된다. 자세하게 파고드는 것은 아니지만 입문자들을 위한 강의인만큼 첫 시작으로 하기에 맞춤인 것 같다.
앞뒤가 다른 것 같지만... 앞선 글에서는 수학,&통계적 지식을 강조했지만 이번에는 "프로그래밍"의 중요성과 필요성에 대해 느꼈으면 좋겠다. 3번째 글인 이 글 까지 봤다면 대략적으로 무엇이 중요한지 감이 올 것 이다. 바로 수학&통계적 지식, 프로그래밍 지식, 도메인 지식, 3가지의 지식이 빠짐없이 중요하다는 것이다.
머신러닝을 꿈꾸는 사람이라면 기초를 탄탄하게하여, 멀리보고 공부한다면 언젠가 그 보상을 눈 앞에 마주하게 될 것이다!