이번엔 R Programming !
이전의 게시글에서는 Python을 이용하여 타이타닉 생존자를 맞춰보았다. 어떤 한 사람에 대해서 생존했는지, 아닌지를 알기 위해서는 학습한 모델을 기반으로 Scoring하면 그 정확도에 맞는 결과를 보여줄 것 이다. 그리고 이번 게시글은 R Programming을 이용하여 타이타닉 생존자를 예측 할 것이다. 분석의 과정은 Python을 통해 한 것과 매우 유사하다.
하지만 이번 R을 통한 분석에서는 분류기법인 Logicstic Regression을 통해서만 알아볼 것 이다. 데이터의 경우는 케글(https://www.kaggle.com/c/titanic)에서 다운로드 받을 수 있다. (앞선 파이썬의 데이터와 조금 다를 수도 있다)

R로 분석하기!
데이터 구조 확인
df.train <- read.csv('titanic_train.csv') head(df.train) |

먼저 titanic_train 데이터를 불러와서 df.train에 저장시킨 후 데이터의 모양을 파악하기 위해서 head를 써서 추출하였다.
변수에 대한 설명은 다음 게시글을 참고하면 될 것 같다

그 이후에는 Python에서 한 것과 마찬가지로 데이터 파일에 Missing Data가 있는지 파악을 해야한다.
library(Amelia) missmap(df.train, main="Titanic Training Data - Missings Map", col=c("yellow", "black"), legend=FALSE) |

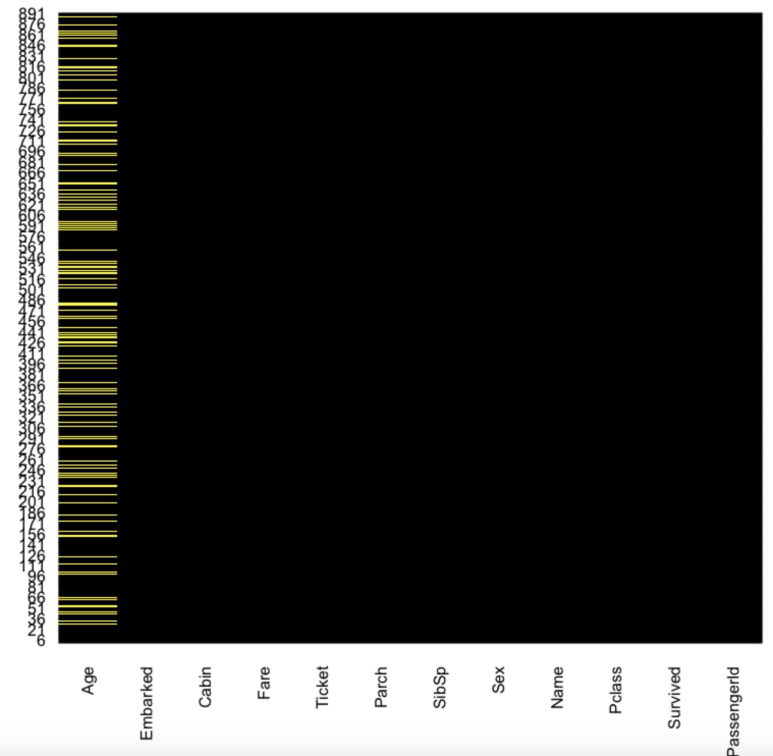
대략적으로 Age 데이터의 20%가 Missing Data이다. 이 Missing Data들은 이후에 Data Cleaning과정을 통해서 처리될 것 이다.
나머지 데이터들은 시각화를 통해 파악해보자. 시각화는 R에서 사용할 수 있는 ggplot2 패키지를 이용할 것 이다.
ggplot2를 이용한 시각화
library(ggplot2) ggplot(df.train,aes(Survived)) + geom_bar() |
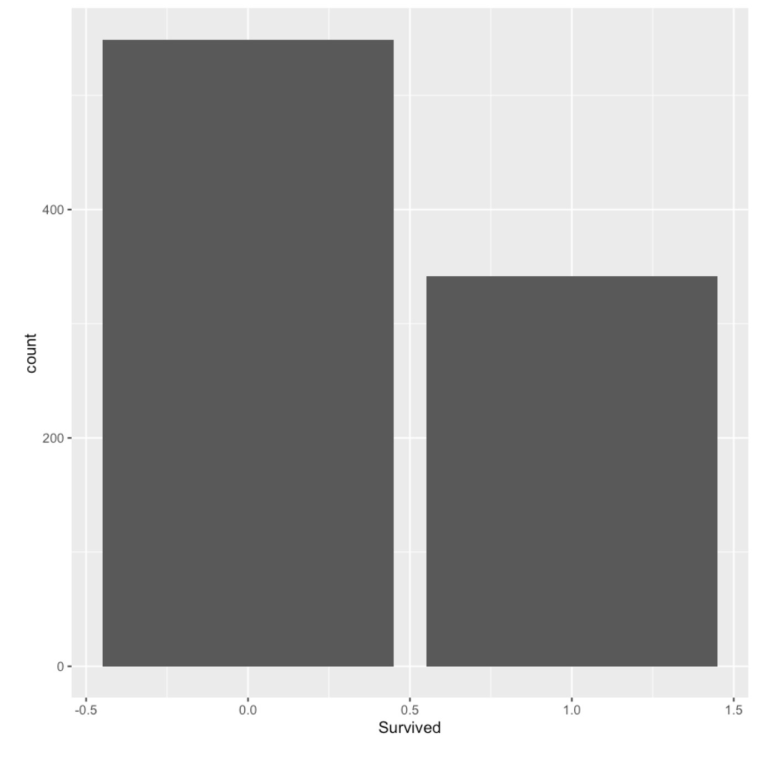
Survived 변수에 대한 count를 barplot을 통해 나타냈다.
ggplot(df.train,aes(Pclass)) + geom_bar(aes(fill=factor(Pclass)),alpha=0.5) |
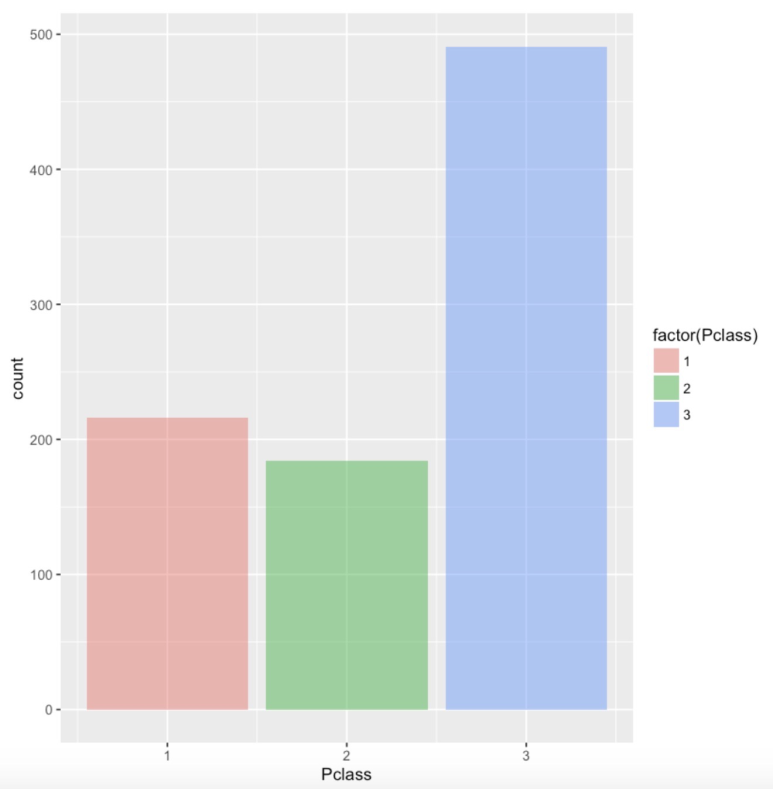
Pclass에 대한 Barplot이다
ggplot(df.train,aes(Sex)) + geom_bar(aes(fill=factor(Sex)),alpha=0.5) |
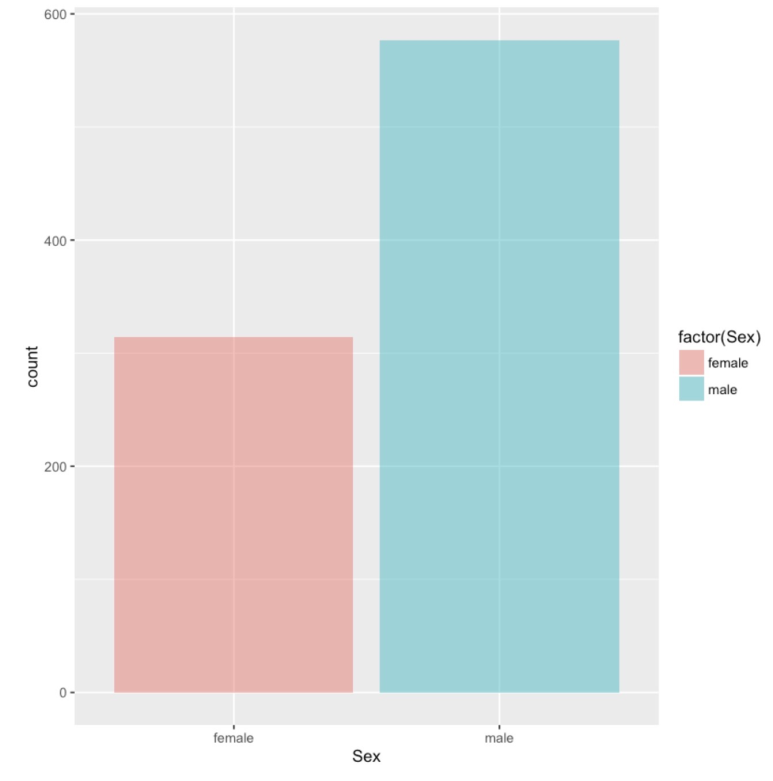
변수 Sex에 대한 분포이다.
ggplot(df.train,aes(Age)) + geom_histogram(fill='blue',bins=20,alpha=0.5) |
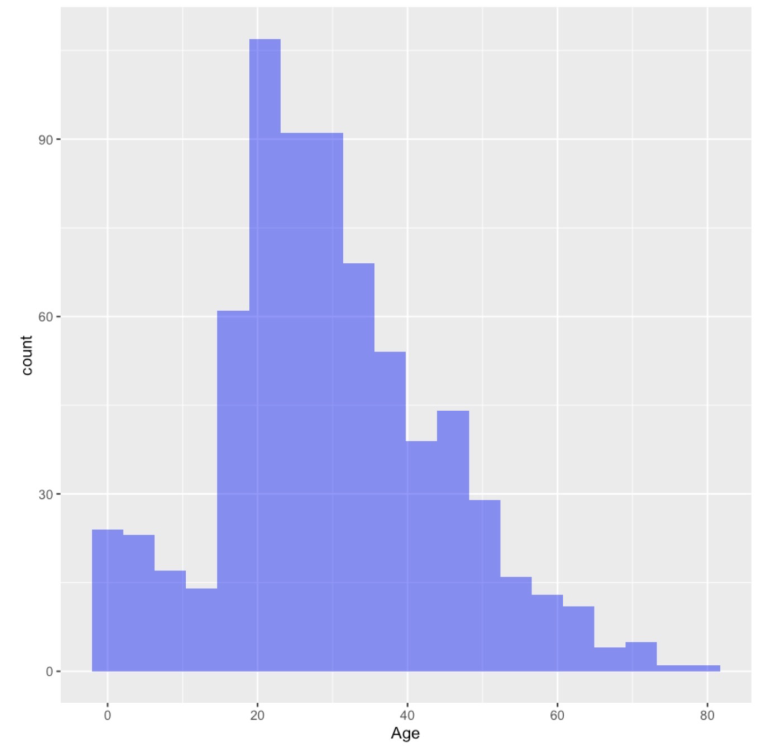
변수 Age에 대한 Histogram 분포이다.
ggplot(df.train,aes(SibSp)) + geom_bar(fill='red',alpha=0.5) |
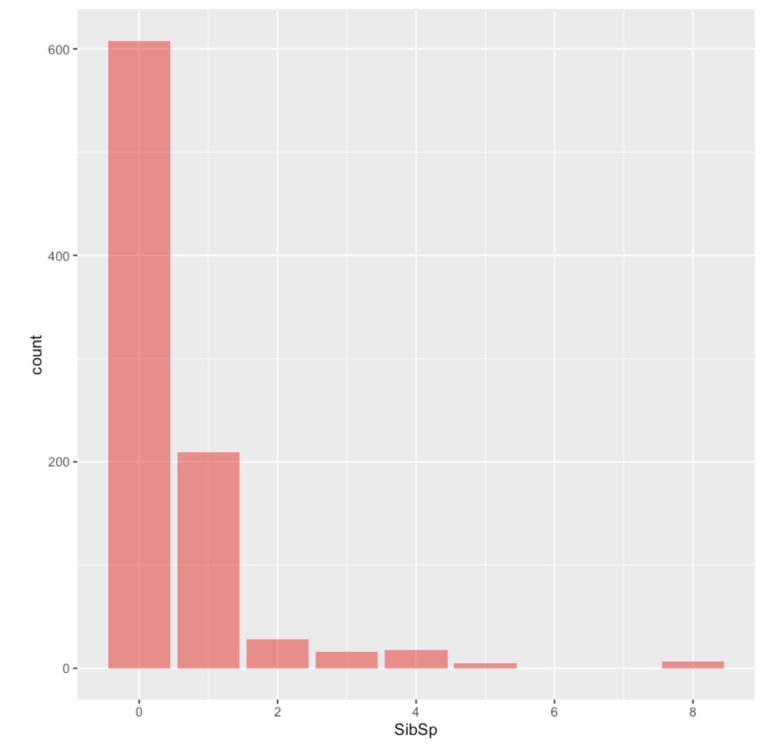
변수 SibSo에 대한 Barplot이다
ggplot(df.train,aes(Fare)) + geom_histogram(fill='green',color='black',alpha=0.5) |
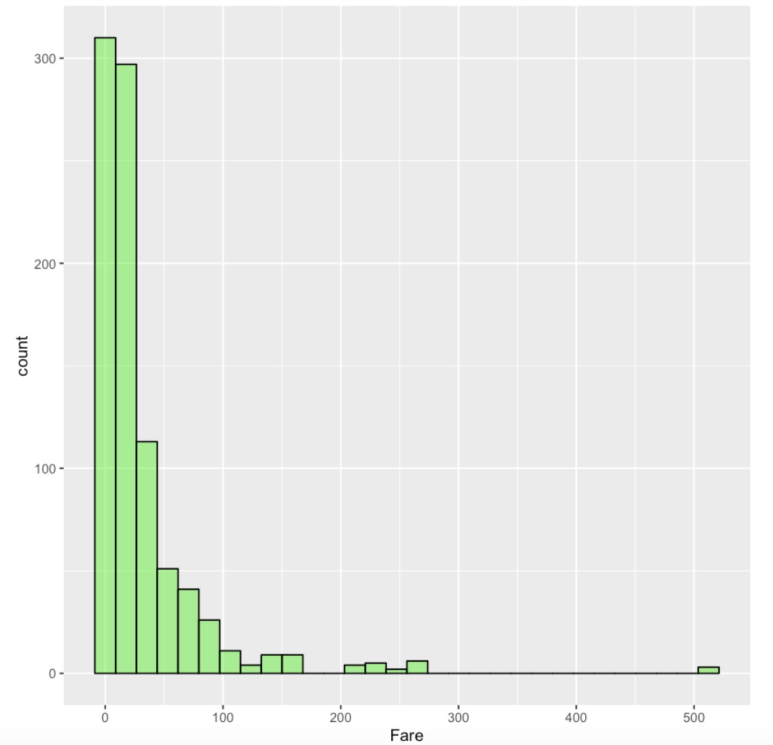
Data Cleaning ( Missing Data 처리하기 )
pl <- ggplot(df.train,aes(Pclass,Age)) + geom_boxplot(aes(group=Pclass,fill=factor(Pclass),alpha=0.4)) pl + scale_y_continuous(breaks = seq(min(0), max(80), by = 2)) |
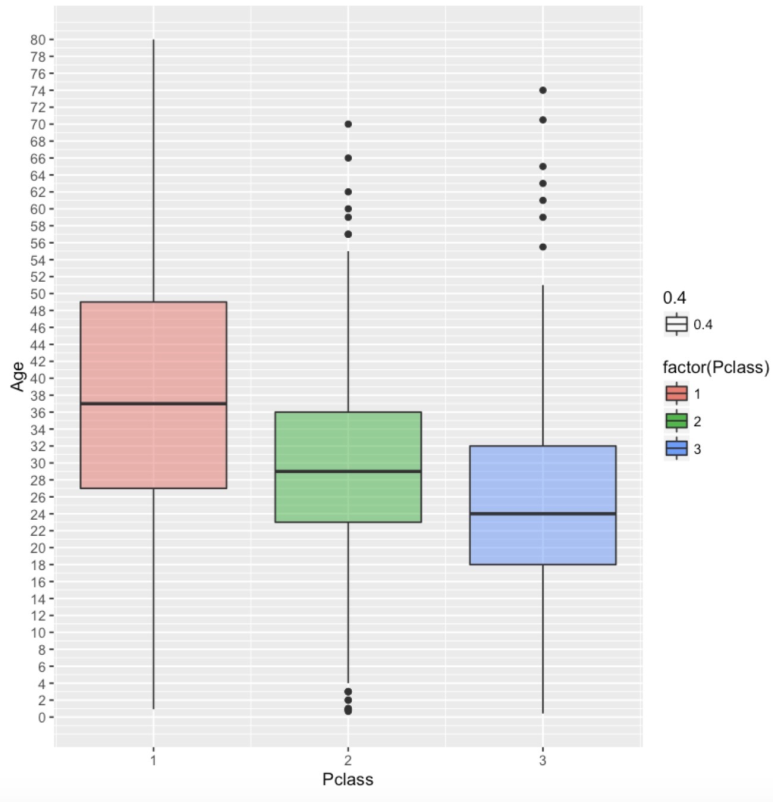
높은 클래스일수록 높은 나이대의 사람들이 차지하고 있음을 볼 수 있다. 따라서 우리는 이 클래스에 기반한 평균나이를 통해 Missing Data를 처리할 것 이다.
impute_age <- function(age,class){ out <- age for (i in 1:length(age)){
if (is.na(age[i])){
if (class[i] == 1){ out[i] <- 37
}else if (class[i] == 2){ out[i] <- 29
}else{ out[i] <- 24 } }else{ out[i]<-age[i] } } return(out) } fixed.ages <- impute_age(df.train$Age,df.train$Pclass) df.train$Age <- fixed.ages |
impute_age를 통해서 기존 데이터의 Age변수의 Missing Data를 채운 것 이다.
missmap(df.train, main="Titanic Training Data - Missings Map", col=c("yellow", "black"), legend=FALSE) |
Age변수의 Missing Data들이 모두 사라진 것을 확인할 수 있다.
Logistic Regression Model 세우기
str(df.train) |

쓰지 않을 변수들은 삭제하기로 하자
library(dplyr) df.train <- select(df.train,-PassengerId,-Name,-Ticket,-Cabin) |
Passengerid, Name, Ticket, Cabin은 분석에서 제외를 했다.
df.train$Survived <- factor(df.train$Survived) df.train$Pclass <- factor(df.train$Pclass) df.train$Parch <- factor(df.train$Parch) df.train$SibSp <- factor(df.train$SibSp) |
그리고 int로 되어있는 변수들을 Factor로 바꾸었다.
모델 학습하기
log.model <- glm(formula=Survived ~ . , family = binomial(link='logit'),data = df.train) summary(log.model) |
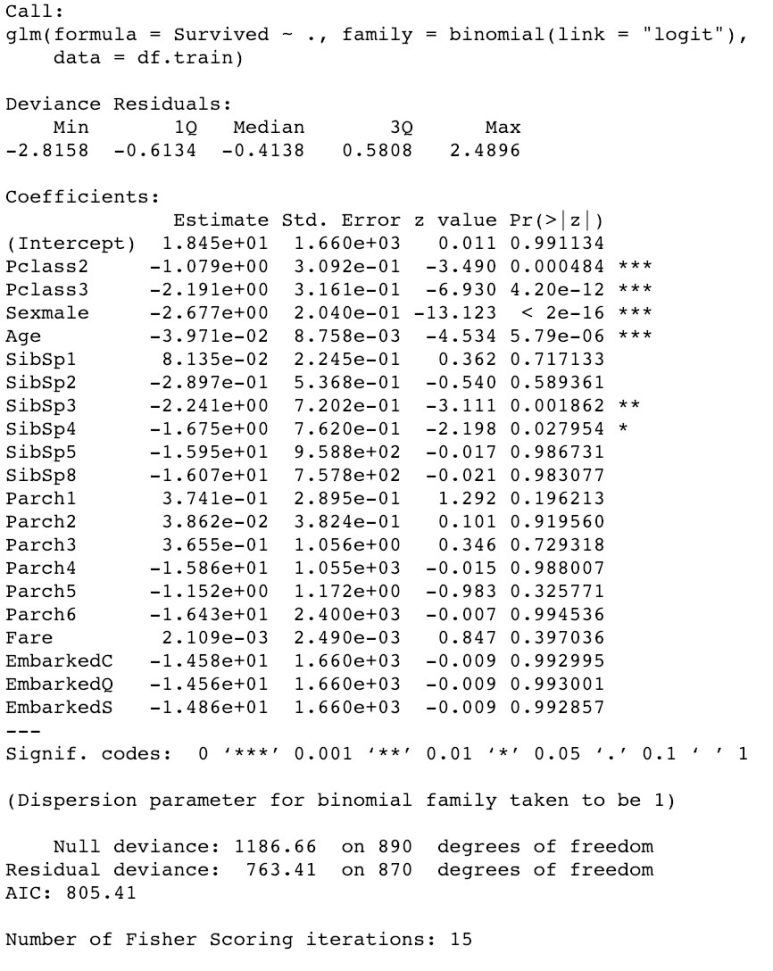
이를 통해 Sex,Age, and Class 변수가 가장 중요함을 알 수 있다.
예측하기
library(caTools) set.seed(101)
split = sample.split(df.train$Survived, SplitRatio = 0.70)
final.train = subset(df.train, split == TRUE) final.test = subset(df.train, split == FALSE)
final.log.model <- glm(formula=Survived ~ . , family = binomial(link='logit'),data = final.train) summary(final.log.model) |
먼저 Logistic Regression을 사용하기 위해 caTools 패키지를 불러온다. 그후 7:3비율로 학습데이터와 테스트 데이터를 나눈다.
종속변수는 역시 Survived로 설정하고 모든 변수를 이용하여 분석을 한다. 그 모델의 요약한 것은 다음과 같다

이제 예측정확도를 확인해보자!
fitted.probabilities <- predict(final.log.model,newdata=final.test,type='response') fitted.results <- ifelse(fitted.probabilities > 0.5,1,0) misClasificError <- mean(fitted.results != final.test$Survived) print(paste('Accuracy',1-misClasificError)) |
0.5이상의 probabilities들은 1로 처리하였다. 이에 대한 정확도는 다음과 같이 나타났다
"Accuracy 0.798507462686567"
80%정도의 정확도를 보이는 것을 확인할 수 있다. 이를 Confusion Matrix를 통해 몇 개를 맞추고 틀렸는지 확인해보자.
Confusion Matrix(혼동행렬)
table(final.test$Survived, fitted.probabilities > 0.5) |

True, False는 모델이 예측한 결과이고 실제 결과는 0,1로 나타나져있다.
0/False , 1/True가 정확하게 맞춘 것이고 나머지는 예측에 실패한 것이다.
이렇게 table함수를 통해 결과를 더 자세하게 볼 수 있었다.
Elice Academy - 문과생을 위한 머신러닝
계획했었던 4주치 문과생을 위한 머신러닝 리뷰가 끝이났다. 게시했던 글이 강의에 있던 내용은 아니지만 강의에 있었던 내용을 기반을 조금 더 나아간 것을 쓰고싶었다. '문과생을 위한 머신러닝' 강의의 경우에는 데이터사이언스에 대해 필요한 그 3가지 분야를 골고루 짚어주고, 그 개념의 범위를 확장시켜주는 것 같다. 조금 더 탄탄하게 다질 수 있는 기회라고 생각을 해본다.
마지막으로 나도 아직 머신러닝에 입문자 수준이지만 이 분야에 뛰어드는 사람들에게 힘내라고 말하고 싶다! 그리고 모두가 열심히 공부해서 새로운 모델이나, 새로운 모듈을 만드는 그런 좋은 방향으로 발전했으면 좋겠다. 그러기 위해선 앞에서 계속 말했던 도메인 지식! 수학&통계적 지식! 프로그래밍 능력! 이 세 가지를 끊임없이 파고들고 끊임없이 연구해야할 것이다!

문과생을 위한 머신러닝 : https://academy.elice.io/courses/536/info
엘리스 홈페이지 : https://academy.elice.io/explore