![[iOS] WWDC16: Understanding Swift Performance 1](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdkbYxP%2Fbtrq23Dud67%2FAAAAAAAAAAAAAAAAAAAAAKGksphK1IJrl0O9Yulep0IH6gTIdf5TFIZLj9BgnBu3%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DwkEskuzCou8gE3YO8hbqsTgXwjo%253D)
WWDC16: Understanding Swift Performance 1

Swift의 여러 타입들 가운데 어떤 타입을 써야할지는 여전히 매번 고민이되는 주제이다.
참조가 필요없으니까 값 타입을 쓰거나, 복사가 필요해서 값 타입을 쓰는 등 보통은 단순한 이유에서 타입을 선택하기도 한다. 이에 본 세션에서는 나름 이유를 가지고 타입을 선택할 수 있도록 도움을 주고 있다.
0. 타입을 선택하는 기준

바로 모델링과 성능을 고려하여 타입을 선택할 것을 이야기하고 있는 것이다.
이번에는 모델링은 제쳐놓고 성능에 대해서만 이야기를 나눠본다.
주로 이야기 할 부분은 총 세 가지로 나뉜다.
- Allocation
- 메모리 할당에 관한 부분
- Reference Counting
- 참조 관리에 관한 부분
- Method Dispatch
- 어떤 메서드가 실행되어야하는지를 알아내는 부분
이 세 가지 관점에서 타입의 성능을 판단하게 되는데 그림으로 보면 다음과 같다.

Allocation의 경우 stack 영역에 메모리가 할당되는지, heap 영역에 할당되는지 여부를 나타낸다. Reference Counting은 참조 관리의 빈도에 대해서 나타내며, Method Dispatch의 경우 정적(static)인지, 동적(dynamic)인지를 나타낸다.
해석하는 방법은 간단하다. 우측으로 향할 수록 성능이 좋지 않은 것이다.
자세한 그림은 아래 설명과 함께 보자!
1. Allocation
메모리 할당(Allocation)의 경우, Stack과 Heap 두 가지로 나눠서 볼 수 있다.
먼저 Stack에 대해서 간략하게 알아보자.
1-1. Stack
Stack 영역의 경우 컴파일 타임에 그 크기가 정해지며, 주로 지역변수, 매개변수, 반환값 등이 저장되는 공간이다. 컴파일 타임에 크기가 결정되다 보니, heap 영역과 달리 동적인 할당/해제가 불가능하게 된다.
또한 CPU에 의해 관리되어 heap 영역에 비해 빠른 속도를 가진다는 장점이 있다. 반면에 메모리 크기에 제한이 있다는 단점이 있다.
Stack의 경우 메모리를 할당하기 위해 stack 포인터를 감소시키고, 메모리 해제하기 위해 stack 포인터를 증가시키게 된다.
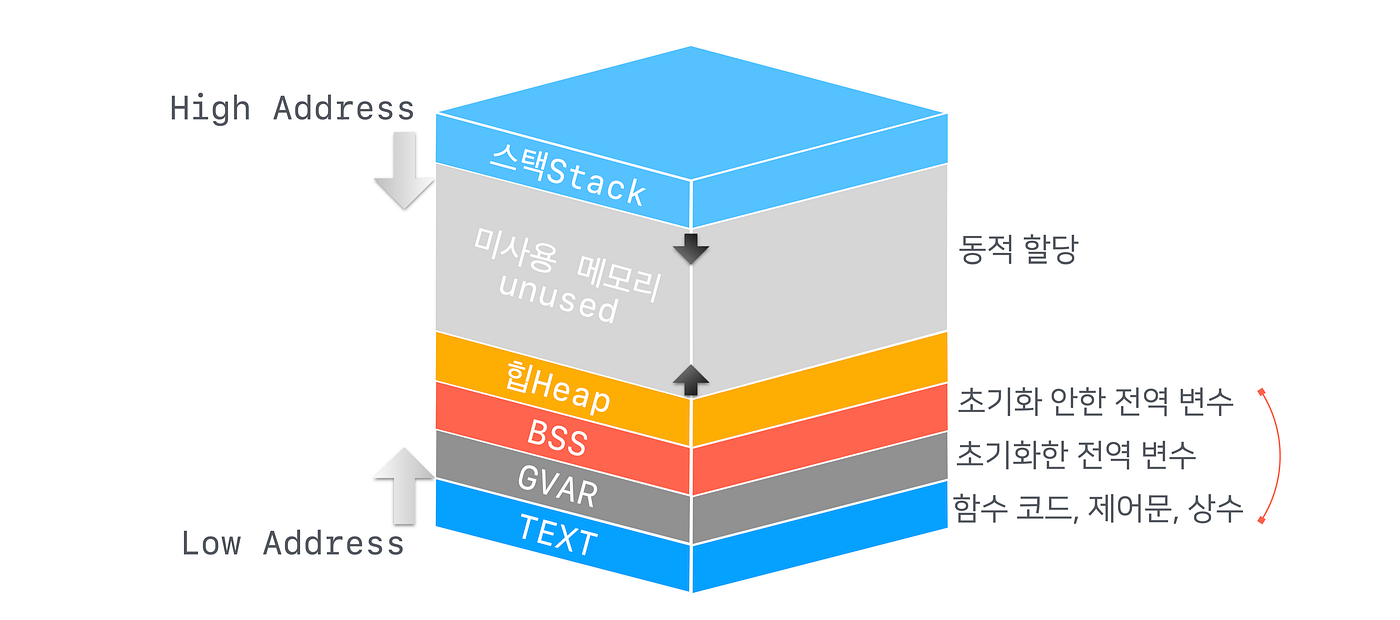
Stack의 경우 높은 메모리 주소로부터 낮은 메모리 주소의 방향으로 채워지게 되는데, 앞서 말한 할당/해제에 따른 포인터의 변화가 이와 맥락을 같이 한다.
즉, stack 메모리에 할당하는 경우 점점 더 낮은 메모리 주소에 가까워지는 것이기에, stack 포인터 또한 낮은 메모리 주소를 가리켜야 한다. 그러기 위해 "감소(decrement)"시킨다는 말을 사요하는 것이며, 당연히 그 반대는 증가(increment)가 될 것이다!
1-2. Heap
Heap 영역의 경우 사용자의 동적 할당에 기반하여 그 크기가 런타임에 결정된다. 위에 그림을 봤듯이 stack과 달리 낮은 메모리 주소에서 높은 메모리 주소의 방향으로 메모리를 차지하게 된다.
이러한 heap 영역에는 클래스의 인스턴스나 클로저 같은 참조 타입이 저장된다. 즉, 참조 카운트(reference count)를 가지는 타입들이 온다는 것이기에, ARC의 대상들이 저장되는 공간이라고도 볼 수 있다.
Stack과 달리 메모리에 제한이 없다는 장점은 있지만, 메모리 할당/해제 작업으로 인한 속도가 저하된다는 단점이 있다.
Heap 영역의 경우 메모리에 할당하기 위해 사용하지 않은 빈 메모리 블록을 찾아야하는 비용이 있다. 또한 해제를 위해 메모리 블록을 다시 삽입해야하는 과정이 존재한다. 그리고 동적으로 할당/해제가 되기 때문에 thread-safe를 보장해주기 위한 overhead까지도 존재한다. (이렇게 보면 단점 투성이...)
이제 stack과 heap에 대해서 봤으니, 이에 저장되는 대표적인 타입인 struct와 class가 어떻게 저장되고 관리되는지 살펴보자.
1-3. Struct와 Class의 Allocation
먼저 struct의 경우를 살펴보자.
1-3-A. Struct

먼저 Point라는 struct 타입의 인스턴스를 하나 만들고, 복사한 모습을 볼 수 있다.
이에 line-by-line으로 어떻게 stack 영역에 할당되는지 살펴볼 것이다.

먼저 point1 인스턴스를 생성하게 되면 stack 영역에 point1의 메모리가 할당된다.

그 다음 point1을 복사하여 point2를 생성하게 되면 이 때도 마찬가지로 point2를 메모리에 할당하게 된다.

그리고는 point2.x = 5를 실행하는데, 값 타입이기에 point2.x 값만 변화한 것을 볼 수 있다.
아는 값 타입의 특징을 매우 잘 보여주고 있다.

이제 point1과 point2를 모두 사용하고 나면 메모리에서 해제된다.
반대로 class는 어떻게 동작할까?
1-3-B. Class

위 사진에 stack 영역이 있다는 것에 의아할 수 있다. 참조 타입은 heap 영역에 저장된다더니... 뒤통수 맞은 기분일 수 있겠지만.. 우선 heap 영역에 할당되는 것은 맞지만, stack에 heap을 가리키는 주소를 저장된다.

point1 인스턴스를 생성하면, 앞선 설명처럼 heap에 그 데이터가 저장되지만, heap을 가리키는 주소가 stack에 저장됨을 볼 수 있다.

마찬가지로 point1을 복사하여, point2를 생성해주면 참조 타입이기 때문에 동일한 heap 메모리 주소를 가리키게 된다.

동일한 메모리 주소를 가리키고 있었기 때문에 프로퍼티의 값을 변경하게 되면 point1, point2의 x 프로퍼티 값의 변경이 일어나게 된다.
class의 특징을 잘 보여주고 있는 것이다!

이제 point1, point2를 모두 사용하고 나면 heap 영역에서 해제된다.

그 이후에 heap 주소를 가리키고 있던 stack 또한 해제되게 된다.
1-3-C. 성능
이제 그림으로 성능을 살펴보면 다음과 같다.

Class는 동적으로 할당/해제가 되기 때문에 많은 비용이 소모된다. 이에 위 그림처럼 나타낼 수 있다.

Struct의 경우 stack영역에 저장되며, 메모리 할당/해제에 별 다른 과정이 없기 때문에 위 그림처럼 나타낼 수 있다.
결론은 Struct가 Class보다 Allocation 측면에서는 성능적으로 더 우월하다는 것이다!
1-3-D. 실제 개선 사례
위에서 구구절절 이야기한 것 처럼 struct가 좋고, class가 allocation 관점에서 좋지 않다는 것을 봤으니 실제 필드에서는 어떤식으로 사용되는지 살펴보자.

Color와 Orientation, Tail을 가지고 말풍선을 만드는 예시이다. 만든 말풍선을 불필요하게 다시 만드는 일을 없도록 하기 위해 cache를 만드는데 key값이 string이다.
String의 경우 struct로 구현되어있지만, 크기가 동적으로 변하기 때문에 컴파일 타임에 그 크기를 알 수 없어 heap 영역을 사용한다고 한다.
이에 String을 사용하는 것을 개선해볼 수 있는데, String이 아니라 아예 타입을 만들어서 해결해볼 수 있다.

이렇게 Attributes라는 struct를 만드는데, 프로퍼티들은 각각 enum으로 구현되어있다. 이에 String 사용을 피할 수 있게 되는 것이다.
2. Reference Counting
우리가 알고 있는 참조 타입에 대한 참조 카운트를 관리하는 것을 말하고 있다. 익히 알고 있겠다싶이 참조 카운트를 관리하는 것에 대한 비용이 존재하며, 무시할 수 없는 정도라는 것도 알고 있을 것이다.
뿐만 아니라, 여러 쓰레드에서 참조 카운트를 올리고/내릴 수 있기 때문에 thread-safe를 보장하기 위한 오버헤드가 발생생할 수 있으며, 참조 카운트를 관리하기 위한 간접적인 단계가 존재한다.
2-1. Class
위에서 봤던 Point 예제를 참조 카운트 관점에서 다시 살펴보자.

ARC 이전에는 직접적으로 참조 카운트를 올려주고 내려주기 위해서 retain/release를 해줬다고 한다(MRC). 하지만 ARC가 등장한 이후부터는 자동으로 이를 해주게 되었는데, 실제로는 눈에 보이지 않는 코드가 작동하고 있다고 봐도 된다.
우측 코드를 보면 인스턴스를 할당하고, 사용을 완료하는 그 사이사이에 retain/release가 들어가 있는 것을 볼 수 있고 Point 타입 내에 참조 카운트가 프로퍼티로 존재하는 것을 볼 수 있다.

실제로 Point1 인스턴스가 생기면 refCount는 1만큼 상승한 1의 값을 가지게 되며 메모리에 할당된다.

이후 Point1 를 복사하여 Point2 인스턴스가 생기면 이 때도 마찬가지로 retain이 실행하기에 refCount는 1만큼 더해진 2가 된다.

이후에 Point1을 다 사용하게 되면 release가 되면서 refCount 또한 1만큼 줄어들게 된다.

Point2도 마찬가지로 사용을 마치면 refCount를 내려주게 된다.
ARC에서 봤듯이 refCount가 0이 되면, 더 이상 필요하지 않은 것으로 인식하고 메모리에서 해제시킨다고 했었다.

이에 다음과 같이 stack/heap 영역에서 모두 매모리 해제되는 것이다.
2-2. Struct
Struct 타입은 기본적으로 참조를 가지지 않기 때문에 참조 카운트 또한 가지지 않는다. 하지만 Struct가 내부적으로 reference를 가지는 경우가 존재하는 데, 이 때는 당연히 참조 카운트를 보유하게 된다.

위 경우 struct 타입이지만 reference를 가지게 된다. 왜냐하면 text는 heap에 할당될 수 있는String 타입이며, UIFont 또한 class이기 때문이다.
그래서 label1 인스턴스를 생성하는 시점에 참조가 하나 생기게 된다.

마찬가지로 label1을 복사해서 label2 인스턴스를 만들 때도 이전에 생성된 주소를 가리키는 참조가 생기게 된다.

실제로 retain/release가 되는 걸 코드로 보면 위와 같다. label1 을 복사하게 되면 프로퍼티 두 개 모두 레퍼런스 카운트가 증가되는 것을 볼 수 있다. 그리고 사용을 마치면 모든 프로퍼티들이 참조 카운트가 1만큼 줄어드는 것을 볼 수 있다.
여기서 알아차릴 수 있는 것은 struct내 참조 타입이 존재할 경우 복사 시에는 매번 모든 프로퍼티의 참조 카운트가 증가/감소한다는 것이다. 이에 유추해보면, 참조 타입의 프로퍼티가 많을 수록 성능이 떨어질 것이라는 것도 유추해볼 수 있다.
2-3. 성능

Class의 경우 참조 카운트를 사용하기 때문에 위와 같이 나타난 것을 확인해볼 수 있다.

반대로 struct는 깔끔하다.
하지만 reference를 가지는 struct의 경우는 어떨까?

음.. struct와 class의 혼종같은 느낌이다.. 앞서 이야기했던 것 처럼 reference 타입을 많이 가지게 되면 좋지 않을 것 같았는데,,,

바로 그림으로 보여주고 있다. 추측했던 것 처럼 struct내 reference 타입이 많아질 경우 성능이 더더욱 안좋아진다는 것을 알 수 있다.
2-4. 실제 개선 사례
참조 타입을 가지는 struct의 예시를 보자.

앞선 말풍선 생성 예제처럼, String이 문제가 되고 있다. 과연 이를 어떻게 개선해볼 수 있을까??

바로 애플이 제공해주는 UUID 타입을 활용함으로써 이를 해결할 수 있다. UUID는 총 36개의 문자로 이루어져있기 때문에 고정적인 길이를 가지는 String이다. 이에 이 경우 heap에 할당되는 것이 아니라 stack 영역에 할당된다.

그리고 mimeType 또한 String이다. 이는 현재 extension을 통해 구현되어 있는데 이 부분은 어떻게 개선해볼 수 있을까??

위처럼 enum 타입을 만들어서 rawValue를 사용해보는 방식을 사용해 볼 수 있다.

그렇게 되면 URL을 제외한 두 프로퍼티는 reference를 가지지 않도록 만들어 준 것이다.
그렇다면 URL은 왜 안바꿔주는가??
마땅한 대체재가 없기 때문이라고 생각한다... 모든 것을 struct로 바꿔서 성능상의 이점을 가져가면 좋겠지만, 이렇게 현실과의 타협이 필요한 부분도 존재하는 것 같다. 이에 URL만이 reference를 가지는 형상으로 개선해볼 수 있다!
3. Method Dispatch
먼저 method dipatch란 무엇일까? 직역해보면 메서드를 붙인다(?)라고도 볼 수 있겠다. 추측을 해보면 메서드가 어디에 붙여질지? 정해주는 역할을 하지 않을까 생각해볼 수 있다.
추측과 조금 유사하지만 메서드 디스패치란, 어떤 메서드 구현이 실행되어야 하는지를 결정하는 역할을 한다.
이 또한 종류가 static/dynamic 두 가지로 나뉘는데 하나씩 살펴보자.
3-1. Static Method Dispatch
말 그대로 뭔가 정적이어서, 정해져있는 고정적인 무언가가 있을 것 같은 느낌이다.
이름처럼 어떤 메서드 구현부를 실행해야하는지 알고 있기 때문에, 이는 런타임에 바로 구현부로 이동할 수 있다. 다시 말하자면 컴파일 타임에 어떤 메서드 구현이 실행되도록 정해져있는 경우를 의미한다고 볼 수 있다.
이에 인라이닝(inlining)이나 다른 최적화를 기대해볼 수 있다.
여기서 인라이닝이란 무엇일까?
위키를 살펴보면 "함수를 함수라는 이름의 몸체의 콜 사이트로 대체하는 수동 또는 컴파일러 최적화 기법이다"라고 설명하고 있다.
알듯 말듯... 모를듯한 느낌...
쉽게 이야기해보자면, 함수 내에 다른 함수가 있는 경우 일반적으로는 이를 실행하기 위해 메모리 주소를 왔다갔다하며 실행하지만 인라이닝의 경우 이러한 비용없이 컴파일 타임에 대상되는 코드를 붙여서 실행해버리는 경우를 의미한다. 이에 call stack의 오버헤드가 줄어들며, 컴파일러의 추가 최적화가 가능해지는 것이다.
더 어려울 수 있지만... 코드를 보면 이해가 갈 것이다.

인라이닝의 예시를 위해 위 코드를 살펴보자.
우선 drawAPoint(point)가 호출되고 있는 것을 알 수 있다. 그러면 우리는 이 메서드가 어떤 역할을 하는지 알아보기 위해 바로 구현부를 찾기 시작할 것이다.
찾아보면 바로 위에 drawAPoint()가 구현되어 있는 것을 볼 수 있다. 구현부를 보니 Point 타입을 파라미터로 받고, 내부에서 .draw()를 호출하고 있다.
흠... 그러면 또 찾아가본다.
보아하니 Point 타입 내에 인스턴스 메서드 draw()가 있는 것을 볼 수 있다. 내부에는 구현부에 대한 내용이 있을 것이다.
지금까지 우리가 살펴본 과정에 의거하면 drawAPoint(point)는 draw()내 구현부로 대체될 수 있다.

그래서 위 처럼 나타낼 수 있는 것이다. 이게 바로 "인라이닝"이다! 나름 더 쉽게 말하자면 메서드의 최상위로 이동하는 느낌인 것이다.
아무튼 static dispatch의 경우 어떤 메서드의 구현부가 오게 될지 알고있다보니 앞서 말한 것 처럼 컴파일러 최적화나, 인라이닝의 장점을 얻을 수 있다.
3-2. Dynamic Method Dispatch
말 그대로 동적으로 메서드 구현부를 찾을 것 같은 느낌이다.
정답!
이 경우 런타임마다 v-table을 통해 메서드 구현부를 찾게 된다. 그 이후 구현부로 이동하여 실행하게 되는 것이다. 이 때문에 인라이닝이나 추가적인 다른 최적화가 어려워진다.(private, final을 사용해서 상속되지 않음을 나타내면 static dispatch를 강제할 수 있긴 하다! 이는 다음에 쓸 글에서 살펴보자...!)
V-Table이란 수직 상속 관계를 포함하는 테이블로, 메서드 오버라이딩에 따라 실행 시점에 어떤 메서드를 실행할 지 결정하는 dynamic diapatch를 지원하기 위해 사용되는 일련의 메커니즘이다.
위에 static을 보면 쉽게쉽게 메서드 구현부를 다 잘 찾아가는 것 같은데 dynamic은 왜 필요한걸까?
바로 상속으로 인한 다형성 때문이다!

상속을 하면 메서드를 재정의 할 수 있게 되는데 이 때 각 메서드들의 구현부가 달라지기 때문에 컴파일러 입장에서는 어떤 메서드 구현부로 이동해야하는지 애매한 상황이 되는 것이다.
위 코드처럼, d.draw()에서는 어떤 draw()의 구현부가 실행될지 모르는 것이다.

for문을 그림으로 풀어서 보면 위처럼 될 것이다. 처음에 해당하는 d[0]은 Line 타입이었다고 해보자. 그러면 이제 컴파일러 입장에서는 맥락을 어느정도 찾게된 것이다.

이제는 V-Table을 통해 어떤 메서드의 구현부가 실행될지 알게 되고, 실행까지 이어질 수 있다. 그래서 이제는 Line
의 draw() 메서드를 호출해 줄 수 있는 것이다.
3-3. 성능

종합적으로 보면 class는 영 꽝인 것을 알 수 있다.

하지만 앞서 말한 것 처럼 final Class를 사용하면 상속이 불가하다는 것을 알려주기 때문에 강제적으로 static dispatch를 사용하여 이점을 얻을 수 있다.
그래서 상속할 일이 없다면 final 키워드를 붙여주라고 했던 것 같다.

마지막으로 struct에 대한 성능을 보면... 그저 뭐 빛이다...
allocation, reference counting, method dispatch 어느 하나 빠질 것 없이 좋은 성능을 보인다. 이러니까 별 목적이 없다면 struct를 기본적으로 쓸 것을 애플이 권장하는 것 같다. 그러니까 우리도 타입을 선택할 때 이러한 성능들을 생각하고 선택하는 습관을 가져야 할 것 같다.
뒤의 protocol types와 generics는 다음에 다뤄보도록 하자!
앞의 내용만 해도 충분히 많고... 중요한 내용인 것 같다.
끄읕!
Ref
https://developer.apple.com/videos/play/wwdc2016/416/
Understanding Swift Performance - WWDC16 - Videos - Apple Developer
In this advanced session, find out how structs, classes, protocols, and generics are implemented in Swift. Learn about their relative...
developer.apple.com
스위프트 타입별 메모리 분석 실험
struct와 class 가 메모리 영역을 어디를 사용하는지 분석한 실험 결과
medium.com